6 建设特色2:异地超算互联互通实现
近年来,随着高性能计算应用场景的增多、规模的扩大,以及数据量的爆炸增长,传统的高性能计算集群已经无法满足日益增长的计算、存储与可靠性需求 ,异地超算集群应运而生。异地超算集群是指在跨区域、或相同区域的不同建筑物内的不同位置,建设多套功能相同、统一管理的集群。异地超算集群相比单个集群能提供更多算力资源,且可配置成互为功能替补或容灾备份的结构,能提高业务的整体算力容量和容灾能力。
如何高效、可靠地管理与使用异地超算集群是一项有挑战的工作。管理员需要协调不同厂商异构计算设备间的互通集成问题,评估长距离网络延时抖动对资源调度和信息同步的影响,设计有效可行的灾备方案,并为用户提供易于使用的多集群操作接口。用户是否愿意将工作负载迁移到新的集群上,将是评估异地超算集群方案有效性的重要指标。
上海交通大学校级计算平台”交我算”由”π 2.0”、“思源一号”等集群构成,分别于2019年、2022年正式上线。 “π 2.0”配备656个计算节点,双精度浮点理论性能达2.1 PFLOPS; “思源一号”配备938个CPU计算节点与23个GPU计算节点,双精度浮点理论性能达6 PFLOPS。思源一号位于张江李政道研究所,距离π集群约50公里。我们在设计异地超算集群管理方案时,希望达到三个目标:一是跨越地理位置上的距离,对两地的计算资源实现统一调度和管理;二是为用户提供便利高效的使用环境;三是利用两地机房物理层面上的独立关系,将整个超算平台改造成高可用的异地容灾系统。
基于以上需求,我们在基础设施、网络互联和容灾能力上做了如下工作:1)在基础设施上,构建了三层互通的网络环境,设置了专用于数据传输的跨存储池数据传输节点,建立了分层汇聚的监控系统;2)在系统软件上,扩展了集群的账号系统、Slurm作业调度系统、可视化平台系统等,形成了跨集群的统一管理,尽可能在集群管理层面屏蔽异地异构集群的底层差异,降低运维难度,最小化用户对新集群的学习与使用成本;3)在业务连续性方面,设计部署了多项异地高可用服务,提升异地集群的容灾能力。
6.1 基础设施统一管理
基础设施统一管理的目标是在集群管理层面上屏蔽异地机房、异构网络、设备型号等底层差异,降低运维复杂度。为此,联合集群在两地之间构建了三层互通的网络环境,增设了专用的跨存储池数据传输节点,融合两地的设备资源,将闵行的账号系统、Slurm作业调度系统、可视化平台等既存系统拓展成跨地域的联合集群。
6.1.1 异地集群网络互联
我们使用虚拟专用局域网(Virtual Private Lan Service,VPLS)技术连接思源一号与π超算两个异地网络。两个集群的边界交换机设置默认网关和路由规则,允许跨集群计算节点在IP层互通,为实现异地集群的统一管理与容灾备份提供了便利。
在设计阶段,我们评估了物理专线、虚拟专用局域网(VPLS)和以OpenVPN软件为代表的虚拟专用网(Virtual Private Network, VPN)技术。各技术方案的特点对比如表6.1所示。由于VPLS 在管理便利性、协议开销和数据安全性上具有优势,且交大网络信息中心与合作电信运营商具有丰富的VPLS配置经验,因此被选为两套异地超算系统的网络互联方案。
| 光纤专线 | VPLS | OpenVPN | |
|---|---|---|---|
| 建设费用 | 高 | 中 | 低 |
| 管理难度 | 低 | 中 | 高 |
| 协议开销 | 无 | 中 | 高 |
| 安全性 | 物理隔离 | VLAN隔离 | SSL加密 |
在实施阶段,VPLS需要先在两个集群各自的汇聚交换机上联口做如下配置:首先,在上联口对应的VLAN中配置一个30位子网掩码的IP地址,并指定往对端集群的静态路由,将上联口设置为trunk模式,并允许内部所有的VLAN透传。其次,请网络运营商在物理链路中的每台核心交换机上添加VPLS配置。最后,测试两个集群的计算节点能否互相ping通管理网络地址。
6.1.2 异地集群数据互通
我们综合考虑了思源一号和π超算的并行文件系统架构、两地互联网络和用户使用习惯,设置了两套并行文件系统,去除耦合独立运行,并仅在集群本地可见。因此,我们需要引导用户在专用数据迁移节点上手动迁移数据,并管理数据在两个文件系统之间的一致性。
在耦合性上,由于两套存储系统在后端网络、文件系统类型上的巨大差异,导致我们无法跨越广域网将两套存储整合在一起。π超算存储使用OmniPath网络技术和开源的Lustre并行文件系统,而思源一号使用Infiniband网络技术和商业版GPFS并行文件系统。在网络互通上,OmniPath和Infiniband不能直接互通,数据需要经过服务器转发后才能到达对方网络。在文件系统类型上,Lustre和GPFS使用独立存储空间和访问协议,无法合并到一个名字空间下,需要用户区分使用这两套存储系统。
在可见性上,两地之间VPLS链路的带宽和延迟,相比集群内要差很多,无法满足HPC作业运行过程中的实施读写需求。尽管通过Ethernet封装等方法可以让所有计算节点都挂载两套超算系统,但是大IO流量下的压力可能会给访问稳定性带来挑战,并有可能拖慢HPC应用的运行速度。
在数据搬移策略上,我们评估了现有主流的开源策略引擎Robinhood多线程并发高速数据传输工具,突破单线程传输瓶颈,能够充分利用集群间的带宽资源。
6.1.3 分层汇聚监控系统
交大计算平台使用Prometheus,以解决单节点监控系统的监控节点数限制,以及现有时序数据库存储时长的限制。
在监控节点数上,受限于拉取数据的网络连接数和网络通信的开销,单个Prometheus节点能监控的节点数通常不超过1000个。思源集群的加入将整个超算平台的节点数量扩大到了2000左右,且其中一半的节点通过VPLS专线与Prometheus数据收集节点相连。在单一Prometheus节点直接监控思源集群节点状态,会产生大量频繁的跨广域网连接会话。这些会话易受广域网波动影响,进而影响监控数据收集的有效性。为解决该问题,我们在π超算和思源一号分别增加一个Prometheus数据汇总节点,负责收集本集群计算节点的监控数据,汇总后回传主节点。引入汇总节点能将大量零散监控通信约束在内网中,同时提前计算关注的监控指标,减少跨域传输的数据量。监控探针、数据汇总节点和主监控节点组成的分层汇聚监控结构如图6.1所示。
在监控数据保存时长上,我们从原有的Prometheus单节点存储,切换到分布式时序数据库Mimir。Prometheus默认使用的本地TSDB(Time Series Database)存储方式受限于单节点的存储空间,缺乏可扩展性和高可用支持。而Mimir在设计上提供了对分布式对象存储的支持,可以解决单节点有限存储空间和监控数据保存时长之间的矛盾。
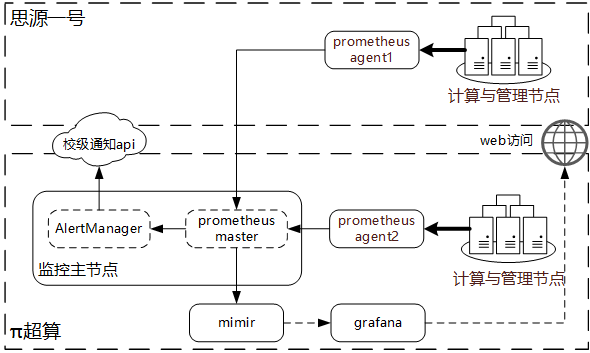
图6.1: 分层汇聚监控系统结构
6.2 系统软件统一管理
Slurm作业调度系统、可视化计算平台和软件模块是超算系统向用户提供的主要操作接口。我们延续π超算系统使用习惯,在同一套Slurm作业调度系统、同一套可视化计算平台下整合两地超算集群,软件模块命名规则保持一致,降低用户使用新平台的学习成本。
6.2.1 Slurm统一调度
我们使用同一个Slurm系统的三个队列(cpu, arm ,ai)分别管理π超算系统下的三个硬件集群(CPU、国产ARM、AI) 。在两地通过虚拟专线网络连通后,我们延续当前模式,将思源一号也作为一个新的计算队列纳入管理。为应对虚拟专线网络波动和集群文件系统隔离带来的问题,我们提高了SLURM节点下线的超时秒数,并定制job_submit插件用于退回不合规作业。
在计算资源集成上,Slurm提供的实现方案主要有两种:联合集群(Federated Cluster) 和新增队列。联合集群方案将相对独立的多组计算资源以组织起来,具有配置独立、调度灵活的优点,但会使平台结构变得更为复杂,增加用户学习成本与运维管理难度。相比之下,新增队列方案不会提高平台结构复杂度,且同样能满足现有的设计需求。其向用户屏蔽了集群地理位置的差异,允许管理员只设置一套资源配额与作业优先级,向后台计费系统提供了唯一接口,是更符合”统一管理”需求的方案。
在用户作业提交上,我们在Slurm作业提交插件job_submit中增加规则,退回工作目录与队列不匹配的作业。当前π超算与思源一号文件系统独立运行,用户需要进入对应集群的工作目录提交作业,才能确保作业正常启动。我们在job_submit.lua检查目标队列和工作目录,当两者匹配时(如64c512g队列对应/dssg工作目录,cpu队列对应/lustre工作目录)允许作业提交,反之则退回,并提示用户登录对应集群重新提交。这个检查规则还可以扩展到其他类型的不合规作业,包括:未申请GPU资源的AI类作业、超长时间作业等。
6.2.2 账号统一认证
我们延续从π超算开始使用的ds389作为LDAP服务端,在各个节点使用SSSD作为对接LDAP的客户端。为实现”统一认证”,即使用同一组账号和密码登录两个超算集群,思源一号也使用SSSD作为客户端对接LDAP服务。除了用户名和密码,LDAP服务还在异地集群间共享了诸如账号有效性、登录Shell、家目录等信息。
由于存储系统独立运行,用户在两台超算上的家目录不同,而LDAP服务遵循RFC规范,不能为同一个用户指定多个家目录。为此,我们在客户端使用SSSD的家目录改写功能,实现了同一个用户在不同集群上使用不同家目录。
具体的,我们在LDAP用户记录的homeDirectory属性中,将两地路径中不相同的部分设置为可替换的%H宏,在各个节点上的SSSD配置中,根据该节点使用的存储池指定不同的homedir_substring变量。在认证过程中,SSSD客户端读取到内容为%H的家目录内容,会自动使用homedir_substring替换,从而得到该用户在该集群上的正确家目录路径。
6.2.3 超算软件部署
整合思源一号后,我们沿用了π超算上三种主要软件提供方式: ①Spack 容器镜像,并且为用户提供了两个平台上的最佳实践文档。
交大计算平台已经为用户提供了超过200种软件,理论上借助丰富的软件仓库,支持的软件总数超2000个。三种软件部署方式被用于不同场景,其中,①Spack适用于依赖关系复杂、性能要求高的基础组件和MPI软件,如GCC、OpenMPI、OpenFOAM等。我们在Spack之上封装了一套软件环境,用于保持两套超算上的软件同步 。②Singularity是基于容器技术的软件封装技术,支持非特权运行,作为Spack软件部署的备选方案,用于复杂的软件依赖和特殊的环境需求场景,例如MATLAB等。③Anaconda提供了大量的预编译软件包,有利于用户方便快速地自行构建所需软件环境,是生物信息学、数据科学类用户的推荐应用部署方式。
在指导用户使用上,超算中心文档中心为同一个软件提供多个平台上的最佳实践用法。以分子动力学软件Gromacs为例,文档中心提供了3个超算平台(π超算、思源一号、国产ARM平台)上的5个可用版本,给出了推荐作业脚本和算例运行时间,帮助用户选择最适合的版本。
6.3 异地超算集群高可用设计
为确保统一管理的两台异地超算系统,在其中一台发生故障时另一台仍能正常服务,我们将集群中的关键服务,包括Slurm、LDAP、DNS做了高可用配置。相比LDAP和DNS的原生高可用特性,Slurm当前只提供对Slurm主控的高可用配置,尚未覆盖其他组件。对此,我们分析了Slurm各组件的工作模式,并对Slurm做了完整的高可用改造。
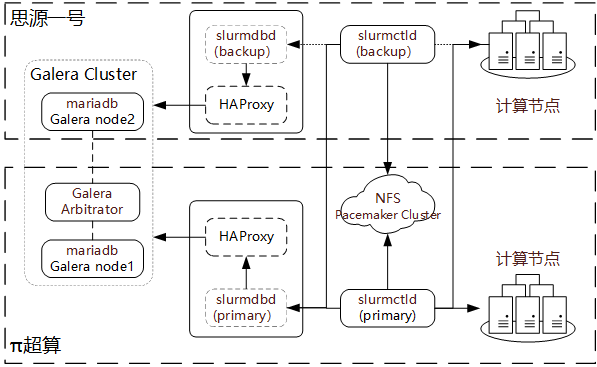
图6.2: Slurm异地高可用结构
6.3.1 高可用Slurm服务
Slurm作业调度系统在正常工作时需要运行slurmctld和slurmdbd两个服务,前者负责接收和启动作业,后者负责记录作业和检查配额。我们分析后发现,将Slurm改造成高可用模式,需要将如下四个组件改造成支持高可用服务的状态:①slurmcltd服务;②slurmctld记录作业状态的文件系统;③slurmdbd服务;④slurmdbd服务依赖的MySQL/MariaDB数据库服务。如图6.2所示,我们对这四个组件做了高可用改造,具体方案如下:
slurmctld主备模式是Slurm原生支持的高可用模式。我们分别在两地部署一个服务节点,其中一个作为主节点,另一个作为备用节点。仅当主节点失去响应达到指定的时长时,备用节点才会切换到主节点角色接管整个Slurm集群。
对于slurmcltd记录作业状态的文件系统,我们在后端通过Pacemaker协调两个NFS节点,向slurmctld提供一个高可用IP地址连接文件系统。在其中一个NFS节点发生故障时,由Pacemaker自动触发保护倒换过程。
slurmdbd采用与slurmctld类似的高可用机制,分别在两地部署一主一备服务。两地的slurmdbd服务分别通过运行在本机的HAProxy代理连接MySQL/MariaDB服务,当其中一侧的数据库失去响应后另一侧能立即接管。
对于MySQL/MariaDB异地高可用设计,我们使用了3台MariaDB组成Galera集群,并通过HAProxy提供固定IP地址服务。我们发现,仅使用2台MariaDB组成的集群,数据复制可靠性不能满足要求,容易发生脑裂问题。因此,我们选择使用3个节点搭建更为可靠的Galera集群结构。除了在π超算节点和思源一号一侧各搭建1个MariaDB节点,还需要在更靠近日常活跃slurmdbd的一侧额外部署一个仲裁节点。
6.3.2 高可用LDAP服务
我们使用389ds的多主节点复制(mutli-master replication)功能构建高可用LDAP服务。
在主从方案设计选型上,我们利用LDAP数据库极低的更新频率、对数据同步高达分钟级的容忍性和一般的可用性要求,选择了架构更简单的多主机读写方案。在更新频率上,LDAP仅在新增用户、更改密码时需要更新同步,据估算每天不超过20次。在状态同步容忍性上,用户收到账户创建或密码重置的通知后,通常会在1-2分钟后才操作,利用这个时间差可以完成数据同步操作。在可用性上,节点SSSD服务会缓存LDAP凭证,最多能容忍约1小时左右LDAP服务下线,无需人工干预。因此,与MariaDB主从数据库相比,我们使用易于实现的多主节点复制技术。
这个方案在两地分别部署一个LDAP服务节点,两者均作为可读写的主节点角色,通过两条方向相反的复制协议互相同步最新数据,确保异地数据一致性。两地的其他节点分别将同地域的LDAP节点设置为首选服务节点,以减少跨地域的网络请求。
6.3.3 高可用DNS服务
BIND域名解析服务器的分布式机制本身已经包含异地容灾的设计。我们在思源一号集群中增设了一台DNS从节点服务器,与π超算上的DNS主节点构成主从高可用写作模式。管理员在更新DNS记录时,首先更新主节点,然后由主节点推送更新至从节点,以此确保两地记录的一致性。与LDAP的低数据更新频次类似,DNS数据仅在新增节点、变更节点IP地址时更新,平均每天不超过10次,对于因DNS主节点下线而不能更新记录的故障,至少能容忍1小时。此外,为了减少跨VPLS专线的网络请求,两地超算节点分别将本地域的DNS服务节点设置为首选节点,将异地DNS服务节点设置为备用节点。因此,主从节点能够满足异地超算DNS服务的高可用要求。