5 建设特色1:以数据为中心的异构超算集群设计
5.1 超算系统综合性能的重要性日渐凸显
传统的高性能计算行业以算力作为核心生产力。进入大数据时代后,数据的规模不断增长。随着数据价值的不断提升以及大数据、人工智能等新兴数字产业的兴起,高性能计算系统的业务负载需考虑HPC、大数据和AI的混合叠加,对于数据的存储和处理能力提出了更高要求。 当数据存力不足或者效率低下时,数据就无法高效流动、按需使用,也就无法充分挖掘其价值,小则影响算力作用的充分发挥,大则关乎整个高性能计算产业的发展。
因此,计算性能不再是评价高性能计算集群的唯一标准,集群的综合性能日益受到重视,尤其是与数据息息相关的存储性能。 存储性能是继计算性能之后,各行各业数字化能力建设的一种进阶,在数字经济发展中至关重要。存储与计算性能高度融合,方能真正形成新的核心生产力,解决许多传统超算算不了、算不准、算不动的问题,在各种业务场景中让效率指数级增加,让生产力获得前所未有的解放。
5.2 数据密集型高性能计算系统的建设理念
传统超算的建设模式通常是”数据跟着算力跑”,即规划和建设超算的重点在于算力,而存力只是依附于算力的一个存储系统。 然而,随着数据的重要性日益增长,高性能计算系统需要转变为”算力围着存力转”(如图5.1所示),从数据密集型角度进行设计,支持应用驱动的科学计算工作流,推动负载从计算科学发现向数据科学发现转变。
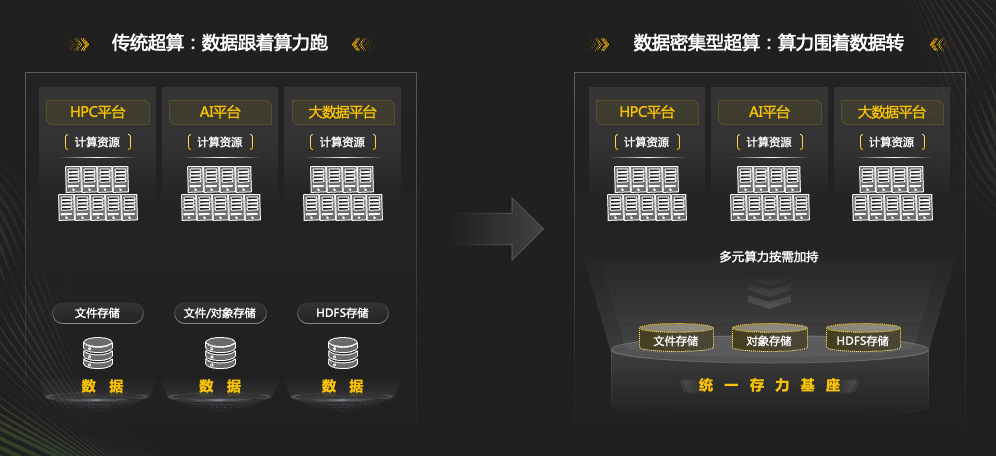
图5.1: 高性能计算系统的演变
平衡存算比是当前超算集群融合存储与计算性能的主要需求之一。目前,芯片不断朝着高性能、低成本、高集成的方向发展,但随着单芯片集成的晶体管数量增多,高耗能等问题随之出现,导致芯片性能难以持续提升,无法大规模提升算力。多芯片堆叠封装为芯片突破性能瓶颈提供了可能,平衡存算比可有效缩短数据搬运路径,降低搬运功耗,实现芯片级算力与IO的平衡。从设备内视角来看,CPU、总线速度、主内存带宽及容量的发展速度不一,尤其是在处理海量数据过程中,内存与存储的空间和带宽成为制约性能增长的主要瓶颈,如果存储设备能平衡CPU和IO性能,将在很大程度上释放算力潜力。
此外,随着数据量的增加,数据处理和存储的效率也需要及时跟进。在多样化的HPC场景中,产生的数据量可达PB级,需要超大的容量方能完成归档。除此之外,在海量数据处理过程中,数据可能需要经过多种格式的转换,需要耗费大量的时间,其中还会损坏部分数据,而且产生的数据冗余也占用了宝贵的存储空间。因此,存储设备实现多协议互访可有效提升数据结构多样化的处理效率。
5.3 构建冷热分层的存储系统
5.3.1 冷存储建设背景
2022年前,交我算平台的设备集中在闵行,因此在闵行配备了25PB的Lustre主存储池,辅以300TB的Lustre全闪存高速存储池和4PB的Lustre归档存储池。2022年,随着思源集群的建成,平台在张江增设了10PB的GPFS主存储池。
随着”交我算”平台的用户对存储需求的增长,已有的存储容量即将无法满足用户的需求。在过去的两年间,每年新增的数据量高达8PB,若不进行扩容,至2024年底,存储总量的缺口预计将达约14PB。
由于高性能计算业务对存储的读写速度有很高的要求,热存储需要通过OPA或Infiniband等专用高速网络与计算节点通信,无法借用传统的以太网向远距离的异地节点直接提供数据。在计算资源分布在异地机房的情况下,暂时无法将各地的热存储设备整合成统一的存储池。
同时,根据数据分析与用户调研,发现在”交我算”文件系统中,超过6个月未被访问的”冷数据”占总量的41%以上,其中实验数据占了90%,包括实验获取的原始数据、以及计算获得的过程或结果数据等。这些数据需要长时间的归档保存,但是使用的频率较低。
为此,2023年,交我算平台在主力的热存储池之外,增设了对速度要求不高的冷存储,用于替换超期服役(2016年上线)的归档存储池,以便向整个异地分布式集群提供全局可见的统一存储空间。
5.3.2 冷存储建设方案
我们对于国外超算中心的存储系统开展了调研,如图5.2所示,许多国际知名超算中心的存储系统冷热比均在2:1以上,“交我算”的0.1:1与之仍存在不小的差距。
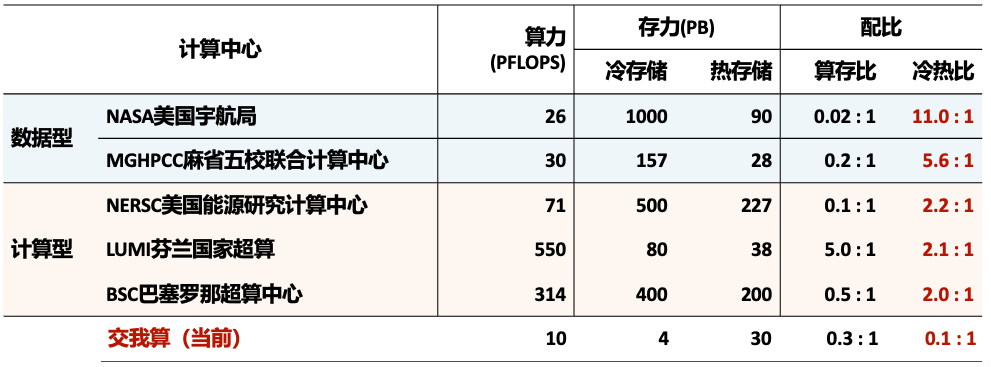
图5.2: 国外超算中心的存储系统调研情况
根据我们对用户的调研,如图5.3所示,有大约10.7PB(裸盘)的数据等待迁移至冷存储。同时,满足至2024年12月新增的冷数据的存储需求,还需准备额外的12.8PB(裸盘)容量。因此,本次建设总共需要23.5PB的裸盘容量。我们选用了超高密度的磁盘阵列,具体选型方案如图5.4所示。

图5.3: 冷存储容量估算

图5.4: 冷存储系统选型
冷存储的建设经历了方案设计、机房改造、设备到货调试、试运行、对外服务5个阶段,在机房改造完成3个月后完成建设流程,开始正式对外服务。
当前的冷存储系统初步满足了超算集群数据冷热分层的需求,走出了统一存力基座的第一步。
在后续的2-3年内,“交我算”的存储系统建设将看齐国外超算中心,继续进行扩容(如图5.5所示),打造一个以冷存储为主的、算存比合理的超算系统。
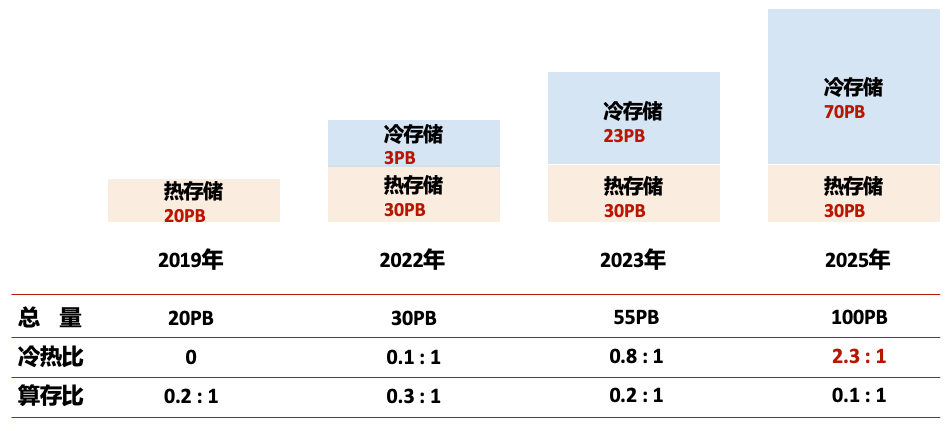
图5.5: 冷存储建设规划
5.3.3 “交我算”当前存储系统一览
“交我算”当前的存储系统(拓扑和配置如图5.6、表5.1所示)由闵行和张江的两个站点、总共4套并行文件系统组成。
位于闵行、张江站点的文件系统不直接互通,编号1-3的文件系统用于计算过程中读写数据,已下线的编号4文件系统曾用于归档冷数据,新上线的编号5文件系统兼顾计算和归档用途。
其中,编号1文件系统挂载到张江站点的所有计算节点上,节点总数约938个;编号2、3位于闵行的文件系统,被挂载到到闵行站点的所有计算节点上,总数约756个。
闵行、张江两地各配置了一个专用数据传输节点,两个节点通过10G虚拟专线互通。数据传输节点使用TCP协议挂载编号1-4的GPFS和Lustre文件系统,用于在文件系统间互通数据。两个数据传输节点间实测数据传输速率约800MB/s。
编号3为全闪存文件系统,每隔一周自动清理旧数据。编号5为冷存储系统,每周做1次数据快照,快照会保留6个月。
编号1-5拥有独立的namespace(或者说”入口”),用户在每个文件系统上都有自己的家目录,用户需要手动管理这些家目录上的数据。用户使用超算完成计算任务的一般流程如下:
- 选定计算站点。根据任务规模、数据大小、站点负载,选择张江或闵行站点。
- 传输数据。用户既可以从台式机将数据传输到所选站点的文件系统上,也可以通过专用数据传输节点在闵行和张江互传数据。
- 运行计算任务。用户远程登录所选站点,进入数据所在文件系统,提交计算任务。任务被调度到计算节点后,计算节点将从该文件系统读取数据、写回结果。
| FS编号 | 位置 | 类型 | 介质 | 容量 | 网络 | 备注 |
|---|---|---|---|---|---|---|
| 1 | 张江 | GPFS | HDD | 10PB | 100G Infiniband | |
| 2 | 闵行 | Lustre | HDD | 25PB | 100G OPA | |
| 3 | 闵行 | Lustre | SSD | 0.3PB | 100G OPA | |
| 4 | 闵行 | Lustre | HDD | 4PB | 10G Ethernet | 2023年8月下线 |
| 5 | 闵行 | 华为DFS | HDD | 23PB | 40G Ethernet | 2023年6月上线 |
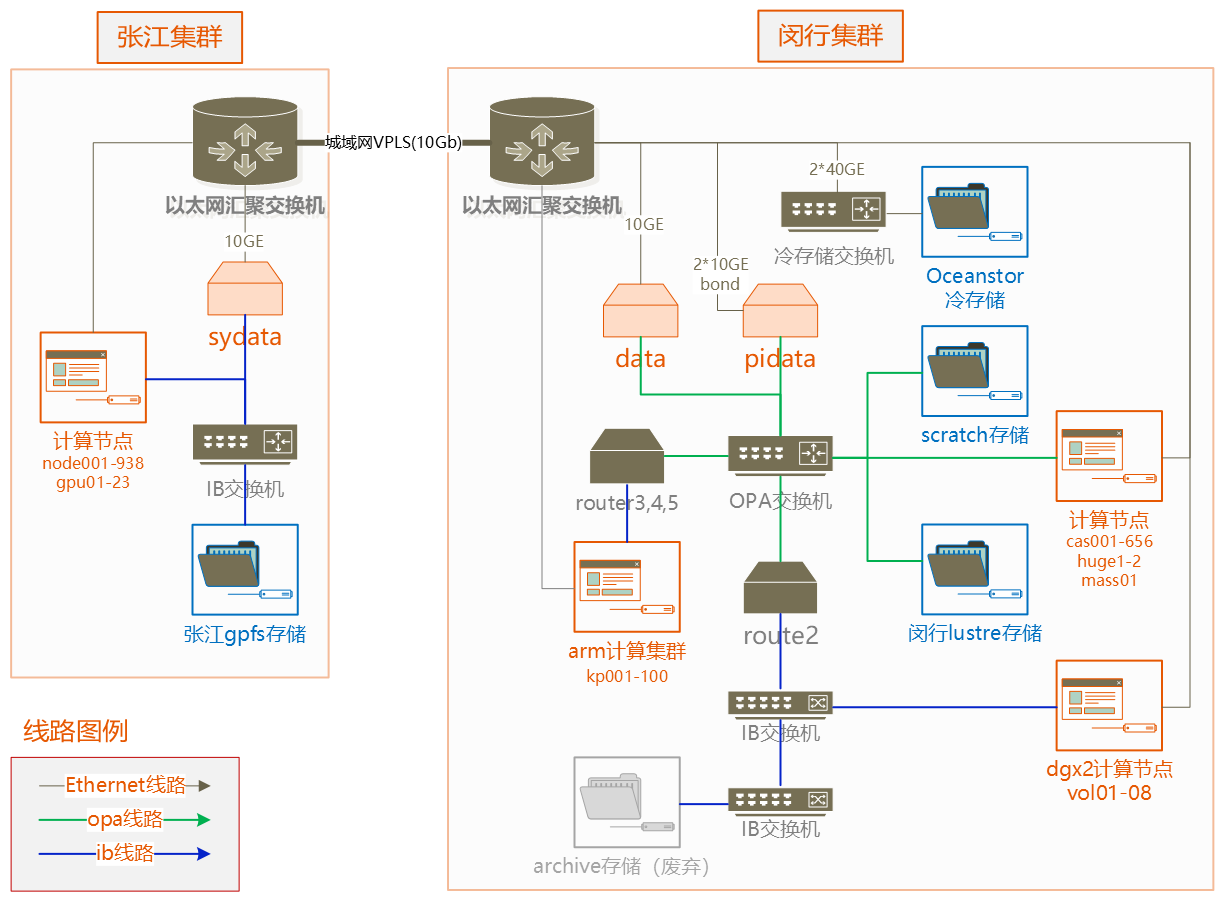
图5.6: “交我算”存储拓扑图
5.4 未来展望:构建超算统一存力基座
“交我算”目前使用中的4台文件系统异地分离(闵行与张江)、冷热共存(SSD与HDD),尚未能够建立起可靠的冷热数据自动迁移机制,用户需要手动管理4套文件系统上的数据,容易导致如下问题:
- 数据找不到。如果用户记不清数据放在哪个存储上,最坏的情况下,用户需要遍历2个站点上的4个文件系统的家目录,才能找到自己的数据。
- 需要手动清理SSD上的数据。编号3的SSD文件系统每隔一周自动清理旧数据,用户要记着及时把数据从SSD搬到其他长久存储文件系统。
- 存算分离。用户数据分割在两地,当计算资源与数据资源所在地不一致时,需要调整资源或者搬移数据。
针对异地异构存储系统、存算分离引发的问题,我们初步设想了如下方法:
- 为多套文件系统设计统一入口,由策略引擎调度下层数据流动。在这个场景下,用户只有一个家目录,在一个文件系统的namespace下访问几套存储。策略引擎修改文件系统元数据中的数据指向,实现多套存储的整合。配合访问频次、冷热特性等策略,策略引擎自动在几套存储间搬移数据,不需要用户手动管理。经过调研,由CEA开发的开源策略引擎Robinhood Policy Engine https://github.com/cea-hpc/robinhood 初步具备这样的特性,但仍存在如下问题:①代码老旧,上一个稳定版于2021年发布;②仅支持Lustre,不支持GPFS;③稳定性差,测试过程中Lustre LLOG写满,导致文件系统下线。
- 编写脚本自动清理SSD数据。编写Shell脚本,在作业启动时把数据搬入SSD,在作业结束后把数据从SSD搬回。
- 存算联合调度。进一步包装计算资源和存储资源,把使用流程中的”选定计算占站点”、“传输数据”合并成一步”提交计算需求”,由作业调度系统按需分配结算节点和存储资源。
我们希望未来能够在冷热数据存储层之间建立全自动的数据迁移和资源调度机制,使得各地的高速对象存储池和全局的低速冷存储有机结合,根据”一存力,多算力”的发展战略,向用户提供一个统一的存储视图。