2 高校超算中心的发展历程——以上海交大“交我算”为例
上海交通大学“交我算”平台是校级计算公共服务平台,由高性能计算中心负责建设与日常管理,全面支撑全校教学、科研、管理等多方面计算需求。
在学校统筹部署下,高性能计算中心秉承“普惠、融合”的建设理念,针对师生的各种计算与存储需求,打造公共计算服务平台底座。自2013年创立以来,经过十余年的建设与发展,已将“交我算”建成为国内高校顶尖的算力基座,具体包括云平台、人工智能计算平台、高性能计算平台等五大计算平台和科学大数据平台;并打造聚合门户,提供统一用户入口,为师生提供“互联网”化的计算服务体验。
2.1 “交我算”发展历史
上海交通大学的高性能计算在过去20年间,经历了一个“合久必分、分久必合”的过程(如图2.1所示)。
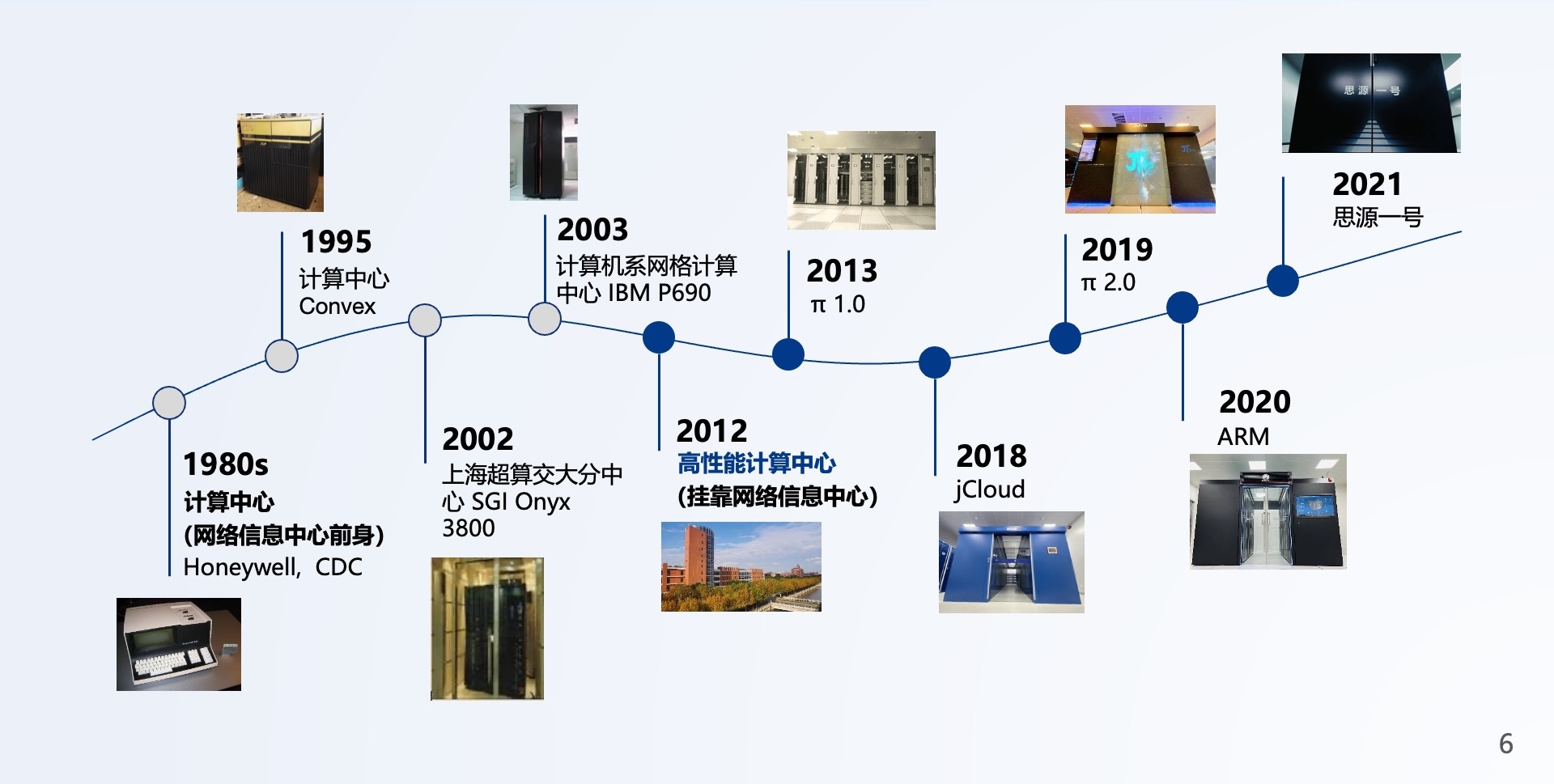
图2.1: 高性能计算中心历史
20世纪80年代中期,前高性能计算研究室主任陆鑫达教授在交大成立高性能计算实验室,并陆续于90年代和00年代购置了6台Sun工作站、一台SGI Onyx 3800,以及一台IBM P690,为全校许多教师提供计算资源。这是因为,当时的高性能计算机价格昂贵,只有高性能计算实验室有能力购置硬件、并持续开展高性能计算方向的研究。
2004年后,随着科研水平的进步,对于计算资源的需求量日益增加。其次,随着集群的大量出现,高性能计算资源的价格越来越低,集群软件和产品经过近10年的发展也都已经足够成熟,学校对计算资源的经费投入也大幅增长,因此各院系自己纷纷购入中小规模集群。
然而,这些集群最终大多疏于管理,利用率低。有鉴于此,上海交大在2012年初成立校级高性能计算中心,挂靠校网络信息中心,为全校提供高性能计算的公共服务。
2013年,搭载了CPU+GPU+MIC节点的异构计算平台π1.0经历了半年的机房改造、组装和调试,最终于7月上线。建成时世界排名为158,位列国内高校第一。
在π1.0运行期间,集群的利用率常年保持在50%~80%之间,处于健康状态。π1.0为上海交大提供了超过5年的计算服务,直到2018年新一期“交我算”算力基座π2.0建成,才宣告退休。
自2018年起,“交我算”的新一代高性能计算平台陆续建成,已为全校用户节省了累计超亿元的计算设备的采购与计算费用。同时,“交我算”团队规模逐步扩张至30人左右,开始发展新的服务模式与运维管理方案,更好地赋能科研创新。
2.2 “交我算”平台现役算力设施
上海交通大学“交我算”平台现役的算力设施如图2.2所示,异构算力包含云计算平台、“思源一号”集群、π2.0集群、人工智能计算平台、国产ARM集群五大平台,总聚合算力 9 PFLOPS(每秒千万亿次)。同时,“交我算”还建设了异构分层的科学大数据平台,当前的聚合存储能力可达65PB。

图2.2: 交我算平台现役算力设施
其中,高性能计算资源配置情况如下:
“思源一号”高性能计算集群建于 2021 年,总算力 6 PFLOPS(每秒六千万亿次浮点运算),是目前国内高校第一的超算集群,TOP500 榜单排名第132位。CPU 采用双路 Intel Xeon ICX Platinum 8358 32 核,主频 2.6GHz,共 938 个计算节点;GPU 采用 NVIDIA HGX A100 4-GPU,共 23 个计算节点。“思源一号”贯彻绿色计算理念,采用联想第五代温水冷技术,与通用风冷计算设备相比,节省电力和减少二氧化碳排放 42%。计算节点之间使用 Mellanox 100 Gbps Infiniband HDR 高速互联,并行存储的聚合存储能力达 10 PB。集群额定功率900kW,其中IT设备额定功率800kW,制冷、配电设备额定功率100kW。单机柜(水冷)额定功率55kW,机柜总数18个,PUE约1.10。
π 2.0 集群建于 2019 年,双精度理论峰值性能为 2.1 PFLOPS,是国内高校和上海地区最快的超算之一。π 2.0 是国内最早使用 Intel Cascade Lake CPU 构建的超算,拥有 656 台计算节点,共计 26240 个 CPU 核,可同时支持 HPC 与 AI 应用。计算节点之间使用 100 Gbps 的 Intel OmniPath 互联。集群额定功率580kW,其中IT设备额定功率350kW,人工智能计算平台额定功率80kW,制冷、配电设备额定功率150kW。单机柜额定功率13kW,机柜总数28个,PUE约1.41。
人工智能计算平台建于 2019 年,双精度计算能力达到 1 PFLOPS,张量计算能力达到 16 PFLOPS,其计算能力由 8 台 NVIDIA DGX-2 服务器提供。每台 DGX-2 配置 16 块 Tesla V100 GPU 加速卡,2 颗 Intel 至强铂金 8168 CPU,1.5 TB DDR4 内存,30 TB NVMe SSD 和 512GB HBM2 显存。数据传输上,GPU 卡之间使用 NVSWITCH 交换芯片实现 NVLINK 高速无阻塞全互联,互连带宽达到 300 GB/s,每台 DGX-2 NVSWITCH 总数达到 12 个,提供 2.4 TB/s 半分带宽;8 台 NVIDIA DGX-2 服务器之间则使用 Mellanox 100 Gbps Infiniband EDR 全线速无阻塞交换机互联。
ARM超算平台是国内首台基于ARM处理器的校级超算集群。平台一共有100个计算节点,单节点配备128核(2.6GHz)、256GB内存(16通道DDR4-2933)、240GB本地硬盘,节点间采用IB高速互联,挂载Lustre并行文件系统。集群额定功率85kW,其中IT设备额定功率60kW,制冷、配电设备额定功率25kW,单机柜额定功率12kW,机柜总数5个,PUE约1.25。